A brief introduction
MBTI, short for Myers-Briggs Type Indicator, is a personality metric developed by Katharine Cook Briggs and her daughter Isabel Briggs Myers, based on Carl Jung’s theory on psychological types. Today, it is a common tool used by individuals and organizations alike, be it to better understand themselves or to optimize workplace dynamics.
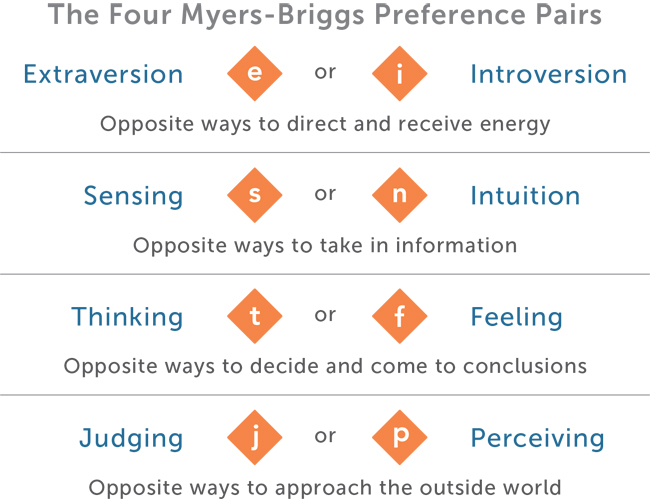
Each person is tested in 4 different areas:
 source: CPP Inc.
source: CPP Inc.
Each person would be typed with 4 letters according to MBTI. So for example for someone whose type is ENFJ, this means that this person is extraverted, intuitive, feeling and judging. I hope this little write-up is succinct enough, but if it is not then please feel free to refer to the official MBTI page to find out more.
The most common way of finding out our type is to visit free personality test websites, where they would require you to answer questions after questions after questions (or statements) in order to determine your type, as accurately as possible. More often than not, these questions relate directly to the type characteristic which requires you to rate how well you ‘relate’ to the question asked. For example:
- My idea of relaxation involves reading a book by the beach
- Strongly Disagree
- Disagree
- Neutral
- Agree
- Strongly Agree
If you haven’t noticed yet, this presents a series of problems, in no order of magnitude:
- We’d inherently know that this question refers to Extroversion/Introversion, and hence may tend to answer based on how we identify rather than purely relating to the question asked.
- In other words, we’d answer with some form of a bias i.e. Who we think we are or want to be vs who we really are.
- I identify as a strong introvert but I don’t really dig reading a book by the beach, nor do people from landlocked areas etc…
- We cannot, in some senses, identify by how much we agree/disagree with the statement/question. However, in order for the model to work, we have to choose a side. Strongly.
- Answering so many questions is already by itself a big time waster, not to mention it being a tiring process.
The question wasn’t picked up from any site in particular by the way, I made it up.
Proposal
My project shall attempt to aid users in having a seamless experience in finding out their MBTI type. Instead of having the user dedicate his/her precious time and brain energy to processing all the questions, the machine only needs to pick up the existing messages produced by the user to predict their MBTI type!
Read on if you would like to understand the how, but beware, it can get a little technical. Meanwhile, I am still in the works of getting a webapp plus a Telegram bot for a comprehensive experience, stay tuned!
How
The model makes use of forum posts from personalitycafe.com for training. Luckily for me, this dataset is already made available on Kaggle in the form of 50 posts per person of a certain MBTI type. Not a competition piece though, just a dataset for us to play around with.
The dataset only consists of two columns, one being the type and the other being the collection of posts made by the person of the type. As such, therein begins my journey of digging out and processing the data from the text followed by modelling and predicting.
Here is a preview of the first line:
type:
INFJ
posts:
"'http://www.youtube.com/watch?v=qsXHcwe3krw|||http://41.media.tumblr.com/tumblr_lfouy03PMA1qa1rooo1_500.jpg|||enfp and intj moments https://www.youtube.com/watch?v=iz7lE1g4XM4 sportscenter not top ten plays https://www.youtube.com/watch?v=uCdfze1etec pranks|||What has been the most life-changing experience in your life?|||http://www.youtube.com/watch?v=vXZeYwwRDw8 http://www.youtube.com/watch?v=u8ejam5DP3E On repeat for most of today.|||May the PerC Experience immerse you.|||The last thing my INFJ friend posted on his facebook before committing suicide the next day. Rest in peace~ http://vimeo.com/22842206|||Hello ENFJ7. Sorry to hear of your distress. It's only natural for a relationship to not be perfection all the time in every moment of existence. Try to figure the hard times as times of growth, as...|||84389 84390 http://wallpaperpassion.com/upload/23700/friendship-boy-and-girl-wallpaper.jpg http://assets.dornob.com/wp-content/uploads/2010/04/round-home-design.jpg ...|||Welcome and stuff.|||http://playeressence.com/wp-content/uploads/2013/08/RED-red-the-pokemon-master-32560474-450-338.jpg Game. Set. Match.|||Prozac, wellbrutin, at least thirty minutes of moving your legs (and I don't mean moving them while sitting in your same desk chair), weed in moderation (maybe try edibles as a healthier alternative...|||Basically come up with three items you've determined that each type (or whichever types you want to do) would more than likely use, given each types' cognitive functions and whatnot, when left by...|||All things in moderation. Sims is indeed a video game, and a good one at that. Note: a good one at that is somewhat subjective in that I am not completely promoting the death of any given Sim...|||Dear ENFP: What were your favorite video games growing up and what are your now, current favorite video games? :cool:|||https://www.youtube.com/watch?v=QyPqT8umzmY|||It appears to be too late. :sad:|||There's someone out there for everyone.|||Wait... I thought confidence was a good thing.|||I just cherish the time of solitude b/c i revel within my inner world more whereas most other time i'd be workin... just enjoy the me time while you can. Don't worry, people will always be around to...|||Yo entp ladies... if you're into a complimentary personality,well, hey.|||... when your main social outlet is xbox live conversations and even then you verbally fatigue quickly.|||http://www.youtube.com/watch?v=gDhy7rdfm14 I really dig the part from 1:46 to 2:50|||http://www.youtube.com/watch?v=msqXffgh7b8|||Banned because this thread requires it of me.|||Get high in backyard, roast and eat marshmellows in backyard while conversing over something intellectual, followed by massages and kisses.|||http://www.youtube.com/watch?v=Mw7eoU3BMbE|||http://www.youtube.com/watch?v=4V2uYORhQOk|||http://www.youtube.com/watch?v=SlVmgFQQ0TI|||Banned for too many b's in that sentence. How could you! Think of the B!|||Banned for watching movies in the corner with the dunces.|||Banned because Health class clearly taught you nothing about peer pressure.|||Banned for a whole host of reasons!|||http://www.youtube.com/watch?v=IRcrv41hgz4|||1) Two baby deer on left and right munching on a beetle in the middle. 2) Using their own blood, two cavemen diary today's latest happenings on their designated cave diary wall. 3) I see it as...|||a pokemon world an infj society everyone becomes an optimist|||49142|||http://www.youtube.com/watch?v=ZRCEq_JFeFM|||http://discovermagazine.com/2012/jul-aug/20-things-you-didnt-know-about-deserts/desert.jpg|||http://oyster.ignimgs.com/mediawiki/apis.ign.com/pokemon-silver-version/d/dd/Ditto.gif|||http://www.serebii.net/potw-dp/Scizor.jpg|||Not all artists are artists because they draw. It's the idea that counts in forming something of your own... like a signature.|||Welcome to the robot ranks, person who downed my self-esteem cuz I'm not an avid signature artist like herself. :proud:|||Banned for taking all the room under my bed. Ya gotta learn to share with the roaches.|||http://www.youtube.com/watch?v=w8IgImn57aQ|||Banned for being too much of a thundering, grumbling kind of storm... yep.|||Ahh... old high school music I haven't heard in ages. http://www.youtube.com/watch?v=dcCRUPCdB1w|||I failed a public speaking class a few years ago and I've sort of learned what I could do better were I to be in that position again. A big part of my failure was just overloading myself with too...|||I like this person's mentality. He's a confirmed INTJ by the way. http://www.youtube.com/watch?v=hGKLI-GEc6M|||Move to the Denver area and start a new life for myself.'"
Wow. Imagine 8675 times that chunk of text!
TL;DR
If, at this point, you are already feeling afraid of what is to come, here is pretty much a summary of what I did with the dataset:
- Basic data cleaning (or the lack thereof - its actually quite clean already)
- Extract weblinks from each user, and
- Further divide the weblinks into video, images and others
- For videos, extract video titles from the respective sites (not used)
- For images, extract keywords (not done)
- For other websites, obtain categories (not done)
- Split the target data from 16 categories into 4 binary classifiers (The why will be explained below)
- Extract other metadata:
- Emoticons (eg. :happy:)
- Mentions (eg. @tamagonii)
- Hashtags (eg. #ilovetamago)
- MBTI reference (eg. INFP, ENFJ) (not used)
- Action words (eg. *jumps into the pool and swim away*)
- Enneagram regerence (eg. 4w1) (not used)
- Brackets (eg. [quote])
- Dots count (…)
- Number of words
- Number of word characters
- Number of fully capitalized words (eg. HEY Y’ALL!!)
- Number of characters of fully capitalized words
- Ratio of fully capitalized words vs all words
- Ratio of characters of fully capitalized words vs characters of all words
- Median number of words used per person
- Median number of characters used per person
- Perform Parts-of-speech (POS) tagging to the word document
- For each MBTI type,
- Perform Term Frequency - Inverse Document Frequency (TF-IDF)
- For word range of 1-3, up to 10,000 words/phrases each
- For each word, apply Truncated Singular Value Decomposition (Truncated SVD) to reduce the size to 500 features each, totalling 1500 features
- Pre-process the data:
- Perform Standard Scaling on metadata
- Combine with TFIDF data, and perform MinMax Scaling
- Select 100 best features using chi2 test
- Train the model with Logistic Regression
- Perform Term Frequency - Inverse Document Frequency (TF-IDF)
- Collect instances of all 4 types to predict data from new input data
- Done!
If you haven’t noticed already, I used some ‘big’ words to describe the process. If you would like to learn what they mean and what they do, read on below!
The boring important stuff.
Congratulations for making to this point. From here on, I shall go into a little more detail, the steps taken towards greatness.
Data observation and cleaning
As mentioned, the dataset comes with just two columns: The MBTI type itself and 50 posts made by the person of the said MBTI type.
We have:
- No null values
- Shape = (8675, 2)
- Nothing else significant to note (for now)
Lucky!
Target variable
As with any Machine Learning tasks, we must first define our target variable. There are a total of 16 different combinations of MBTI types, which means we would have a 16-class classification problem to solve-
…or do we?
Here is a breakdown on the number of people per MBTI type (in yellow) contained in the dataset, benchmarked against the global population percentage representation of each type mapped onto the graph (taken from careerplanner.com):
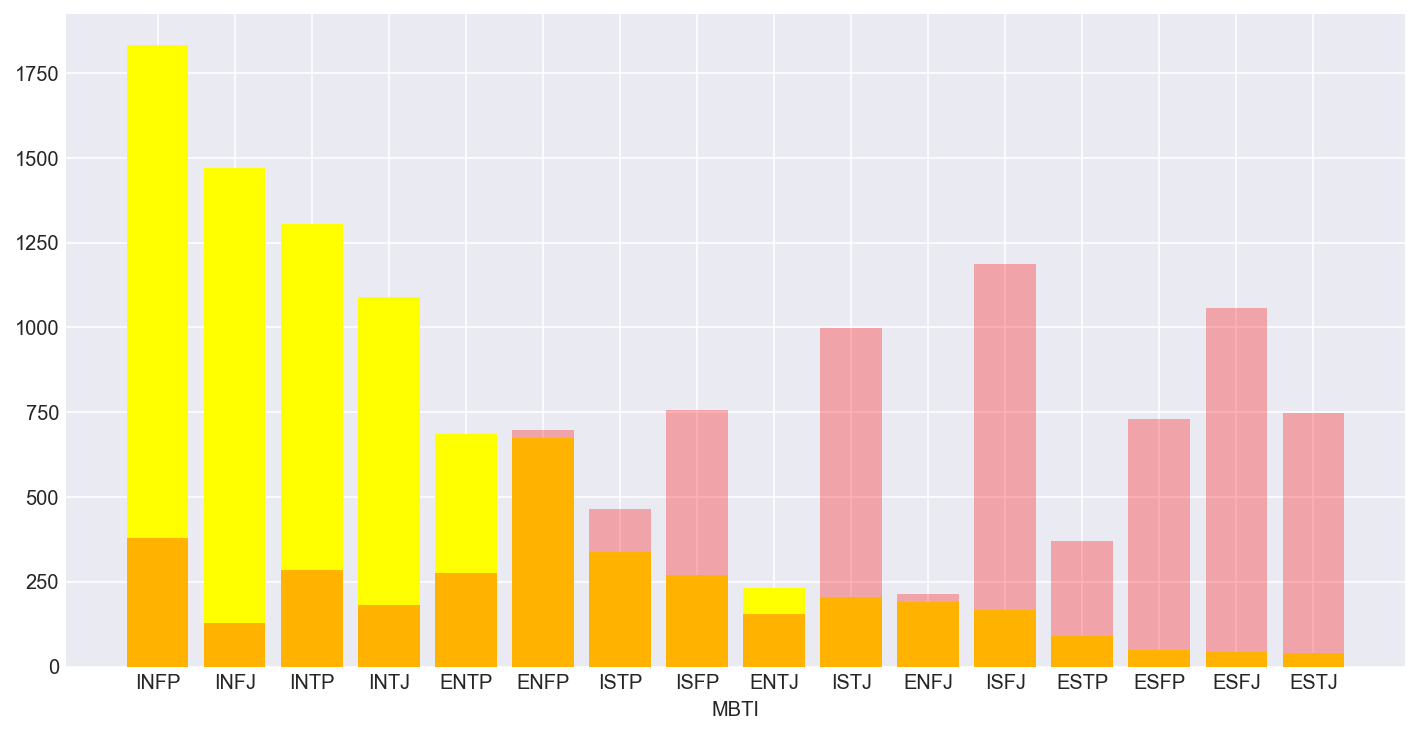
And here is the breakdown of the total number of people of each type in the dataset:
INFP 1832
INFJ 1470
INTP 1304
INTJ 1091
ENTP 685
ENFP 675
ISTP 337
ISFP 271
ENTJ 231
ISTJ 205
ENFJ 190
ISFJ 166
ESTP 89
ESFP 48
ESFJ 42
ESTJ 39
That means to say, if you take the majority (INFP) versus the minority (ESTJ), you get a ratio of 97.9%!
Coincidentally, they are also polar opposites of each other, in terms of type!
On first glance this would look like a very bleak start to the project since it is heavily imbalanced…good luck to me. For my readers who are not so familiar with machine learning yet, having an imbalanced dataset is not good for business in general as the machine will tend to favor the prediction of the majority class, which is kind of ‘normal’ until you realise that they ignore our minority class almost totally. No matter how small the representation, we still want the machine to be able to predict the minority type.
*Ok actually I can fix this*
Instead of doing 16 imbalanced classification head-on, this dataset can be re-classified as 4 binary classifiers!
mbtitypes_all['is_E'] = mbtitypes_all['type'].apply(lambda x: 1 if x[0] == 'E' else 0)
mbtitypes_all['is_S'] = mbtitypes_all['type'].apply(lambda x: 1 if x[1] == 'S' else 0)
mbtitypes_all['is_T'] = mbtitypes_all['type'].apply(lambda x: 1 if x[2] == 'T' else 0)
mbtitypes_all['is_J'] = mbtitypes_all['type'].apply(lambda x: 1 if x[3] == 'J' else 0)
mbtitypes_all.columns = ['type','is_E','is_S','is_T','is_J']
mbtitypes_all.head()
| type | is_E | is_S | is_T | is_J |
|---|---|---|---|---|
| INFJ | 0 | 0 | 0 | 1 |
| ENTP | 1 | 0 | 1 | 0 |
| INTP | 0 | 0 | 1 | 0 |
| INTJ | 0 | 0 | 1 | 1 |
| ENTJ | 1 | 0 | 1 | 1 |
Here we visualize the classifiers once again:
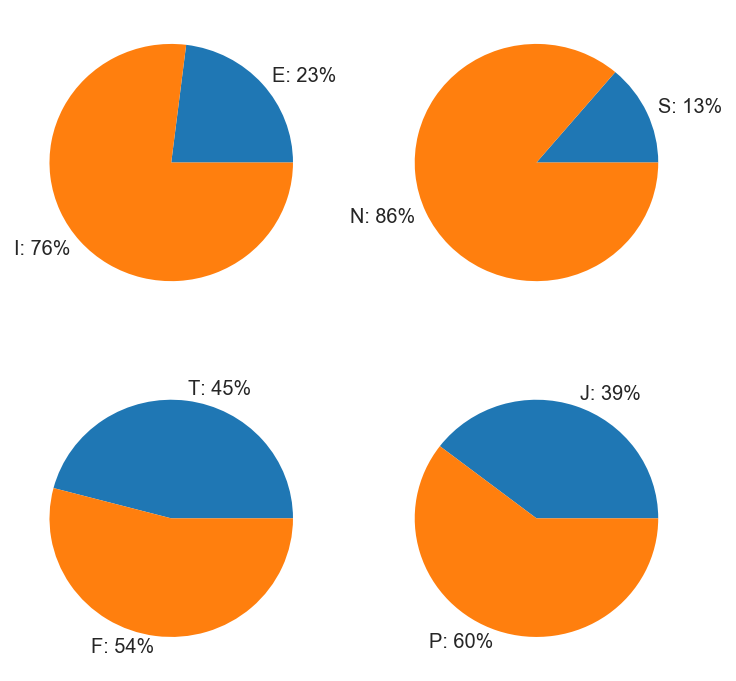
This looks a lot better than the previous 16-class variable, though we still see imbalanced targets for E/I and S/N. We shall deal with them in due time.
Assumption made: Each letter type is independent of other types i.e. A person’s introversion/extraversion is totally not related to their judgement/perception. Nevertheless, we can still test them:
Correlation - How close each feature is affected by another.
For example, if the amount of sales drops/increases definitely with an increase in price, we can say that amount of sales and price are correlated. Whereas in the case where the number of shoppers does not increase/decrease significantly with the changes in pricing, we can say that they have little to no correlation.
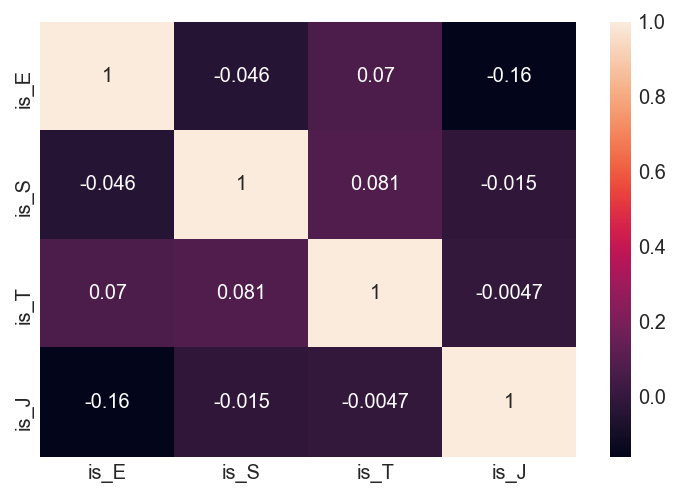
The correlation for all 4 types are very close to 0, which is a good sign.
Features
Time to extract our features!
We first have a cursory look at the text data, which we will see that it is made up of more than mere text alone:
Webpages
- Video links: https://www.youtube.com/watch?v=QyPqT8umzmY
- Image links: http://41.media.tumblr.com/tumblr_lfouy03PMA1qa1rooo1_500.jpg
- Other links: http://phantomshine.blogspot.com/2012/05/writer-analysis-through-mbti.html (taken from another data point) I’ll get to the other data (as mentioned in TLDR) later, I promise.
Video, image and other links can potentially add to the dataset, other than their mere count. We can get video titles from video links, perform image content analysis for image links, or simply category identifying for other links. All these data can potentially be used for topic modelling to find out what kind of topics do people of a certain MBTI type care about collectively that the other type does not care as much about.
Unfortunately I only went as far as extract the video title and nothing else. Sorry…
Other Metadata
Once again, you may notice other non-regular text like @mentions, #tags, *emphasis or action words*, :emoticons:, [bracket words], even dot usage (…) etc. For those features I extracted the total count for those features. On hindsight I could have gotten the mean instead, but it was already too late for that decision stage. I managed to ‘fix’ it later on.
I also extracted the number of MBTI mentions (since the dataset was from a personality discussion forum) and Enneagram references. Sidetrack - The Enneagram is another form of personality typology which could potentially serve as my next project, but not now. Priorities. Meanwhile, you may also take the test if you are interested :wink:
Other data available includes word count, character count, number of fully capitalized words (that are not MBTI references) etc which are also incorporated as features.
Here’s a cursory view of the dataframe after the processing:
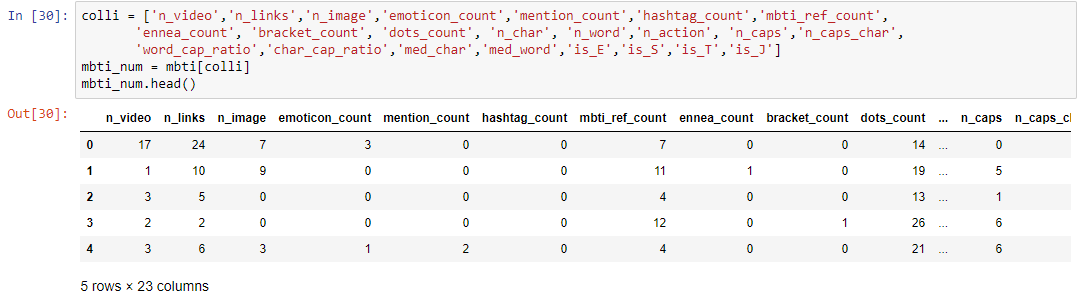
Parts of Speech (POS) tagging
Parts of Speech or POS tagging is used for identifying the type of words within a sentence. For my use case, the area of interest would be to find out once again if there is any discrimination between the frequency of the type of words used between each MBTI type. I did the POS tagging using the Natural Language ToolKit (NLTK) POS tagger.
import nltk
from nltk.tokenize import word_tokenize
#Takes a long time to run!
mbti['tagged_words'] = mbti['words_only'].apply(
lambda x: [nltk.pos_tag(word_tokenize(line.decode('utf-8', errors='replace'))) for line in x])
mbti['tagged_words'][0]
Output of first 5 lines (First 2 lines contain only links which are promptly removed):
[[],
[],
[(u'enfp', 'NN'),
(u'and', 'CC'),
(u'intj', 'JJ'),
(u'moments', 'NNS'),
(u'sportscenter', 'MD'),
(u'not', 'RB'),
(u'top', 'VB'),
(u'ten', 'NN'),
(u'plays', 'NNS'),
(u'pranks', 'NNS')],
[(u'What', 'WP'),
(u'has', 'VBZ'),
(u'been', 'VBN'),
(u'the', 'DT'),
(u'most', 'RBS'),
(u'life-changing', 'JJ'),
(u'experience', 'NN'),
(u'in', 'IN'),
(u'your', 'PRP$'),
(u'life', 'NN'),
(u'?', '.')],
[(u'On', 'IN'),
(u'repeat', 'NN'),
(u'for', 'IN'),
(u'most', 'JJS'),
(u'of', 'IN'),
(u'today', 'NN'),
(u'.', '.')]
After a long arduous tagging process plus consolidating all the tags used by nltk on my text dataset, I managed to get the following tags:
['PRP$', 'VBG', 'VBD', '``', 'VBN', 'POS', "''", 'VBP', 'WDT', 'JJ', 'WP', 'VBZ', 'DT', '#', 'RP', '$', 'NN', ')', '(', 'FW', ',', '.', 'TO', 'PRP', 'RB', ':', 'NNS', 'NNP', 'VB', 'WRB', 'CC', 'LS', 'PDT', 'RBS', 'RBR', 'CD', 'EX', 'IN', 'WP$', 'MD', 'NNPS', 'JJS', 'JJR', 'SYM', 'UH']
Mean or Median
We ideally want to use the median value of a statistic as the median value is more resilient towards outliers than the mean. However in our case, as with the tags by nltk plus the meta-features as mentioned above, they do not appear very often which often results in returning a median of 0, which is a difficult number for us to use. For a cursory overview of the stats:
for col in columnname:
newlist=[]
for line in mbti['tagged_words'][0]:
newlist.append(len([x for x in line if x[1]==col]))
print "For "+col+","
print "Sum = ", np.sum(newlist)
print "Variance =", np.var(newlist)
print "Mean =",np.mean(newlist)
print "Median =",np.median(newlist)
print "Standard Deviation =",np.std(newlist)
Out:
For PRP$,
Sum = 16
Variance = 0.3776
Mean = 0.32
Median = 0.0
Standard Deviation = 0.614491659829
For VBG,
Sum = 14
Variance = 0.3616
Mean = 0.28
Median = 0.0
Standard Deviation = 0.601331855135
For VBD,
Sum = 11
Variance = 0.4516
Mean = 0.22
Median = 0.0
Standard Deviation = 0.672011904656
For ``,
Sum = 0
Variance = 0.0
Mean = 0.0
Median = 0.0
Standard Deviation = 0.0
For VBN,
Sum = 18
Variance = 0.5104
Mean = 0.36
Median = 0.0
Standard Deviation = 0.71442284398
On hindsight I could have put this into a dataframe but at this stage…
For each tag, I took the mean and standard deviation as my column features.
I still want to use the median as a determinant. How can I do so? Combine the tags!
For interests sake, here is the full list of tags used by nltk, minus the punctuation tags:
| Tag | Description |
|---|---|
| CC | Coordinating conjunction |
| CD | Cardinal number |
| DT | Determiner |
| EX | Existential there |
| FW | Foreign word |
| IN | Preposition or subordinating conjunction |
| JJ | Adjective |
| JJR | Adjective, comparative |
| JJS | Adjective, superlative |
| LS | List item marker |
| MD | Modal |
| NN | Noun, singular or mass |
| NNS | Noun, plural |
| NNP | Proper noun, singular |
| NNPS | Proper noun, plural |
| PDT | Predeterminer |
| POS | Possessive ending |
| PRP | Personal pronoun |
| PRP$ | Possessive pronoun |
| RB | Adverb |
| RBR | Adverb, comparative |
| RBS | Adverb, superlative |
| RP | Particle |
| SYM | Symbol |
| TO | to |
| UH | Interjection |
| VB | Verb, base form |
| VBD | Verb, past tense |
| VBG | Verb, gerund or present participle |
| VBN | Verb, past participle |
| VBP | Verb, non3rd person singular present |
| VBZ | Verb, 3rd person singular present |
| WDT | Whdeterminer |
| WP | Whpronoun |
| WP$ | Possessive whpronoun |
| WRB | Whadverb |
We can already notice that there are multiple tags for each word type, each having a different function. This discrimination may be important for word generation to teach the machine how to write sentences properly, but once again, this is not my use case.
Now compare that with POS tags by Stanford NLP:
| Tag | Meaning | English Examples |
|---|---|---|
| ADJ | adjective | new, good, high, special, big, local |
| ADP | adposition | on, of, at, with, by, into, under |
| ADV | adverb | really, already, still, early, now |
| CONJ | conjunction | and, or, but, if, while, although |
| DET | determiner, article | the, a, some, most, every, no, which |
| NOUN | noun | year, home, costs, time, Africa |
| NUM | numeral | twenty-four, fourth, 1991, 14:24 |
| PRT | particle | at, on, out, over per, that, up, with |
| PRON | pronoun | he, their, her, its, my, I, us |
| VERB | verb | is, say, told, given, playing, would |
| . | punctuation marks | . , ; ! |
| X | other | ersatz, esprit, dunno, gr8, univeristy |
The Stanford NLP version of POS tagging is more condensed which can lead to more representation. Now, we group them together as such:
#Lets make a dictionary
convtag_dict={'ADJ':['JJ','JJR','JJS'], 'ADP':['EX','TO'], 'ADV':['RB','RBR','RBS','WRB'], 'CONJ':['CC','IN'],'DET':['DT','PDT','WDT'],
'NOUN':['NN','NNS','NNP','NNPS'], 'NUM':['CD'],'PRT':['RP'],'PRON':['PRP','PRP$','WP','WP$'],
'VERB':['MD','VB','VBD','VBG','VBN','VBP','VBZ'],'.':['#','$',"''",'(',')',',','.',':'],'X':['FW','LS','UH']}
…And then get the median and standard deviation for each.
Done.
Term Frequency - Inverse Document Frequency (TFIDF)
This is the golden fine point where I start to deal with the dataset separately across the 4 MBTI types.
Rationale: There is a methodology of how I am going to perform the TFIDF here.
First of all, a one-liner summary about TFIDF: It is a measure for scoring words that appear often in a single document, but very rarely in other documents. Its use can be attributed to, once again for our use case, detecting the words that someone of an MBTI type would use more often collectively as opposed to another.
For each run of the target variable (I’ll start with Introversion/Extraversion), a train test split will be done using stratified sampling, especially important for E/I and S/N target variables. Since each row (or data point) identifies differently with each variable, the collection of rows belonging to X_train in E/I will definitely be different from the X_train of S/N. This is important because I will only use the X_train portion to train the TFIDF model, followed by having the model transform the X_test word data. This measure ensures that the word data in the test set has no role in the dataset training which also means avoiding overrepresentation or overfitting.
And so this is where we start to part ways.
For training purposes we can specify the removal of stop words (Common words such as “a, an, the” etc), a word range (otherwise known as ngram range) and the max number of words/phrases, among other features not as worth highlighting here. Last I ran with an ngram range of 1-3 and no specified max. features, I got around 300,000+ rows in return. It is a miracle my computer did not crash.
To better manage the TFIDF word results while extracting good features at the same time, I would:
- Run the TFIDF model with ngram range of 1, and max. features of 10,000 words/phrases
- Reduce number of features to 500 using Truncated Singular Value Decomposition (Truncated SVD)
- Save both TFIDF and TSVD instances into a list for later use.
For reference, below is the code that runs the mentioned process:
for i in np.arange(1,4):
tfidf = TfidfVectorizer(stop_words='english',ngram_range=(i,i), decode_error='replace', max_features=10000)
Xword_train = tfidf.fit_transform(X_train['words_only'])
Xword_test = tfidf.transform(X_test['words_only'])
#We need to reduce the size of the tfidf trained matrix first
#But after running TruncatedSVD we cannot see the words specifically alr so too bad...
tsvd = TruncatedSVD(n_components=500, algorithm='arpack', random_state=self.random_state)
Xwordie_train = tsvd.fit_transform(Xword_train)
Xwordie_test = tsvd.transform(Xword_test)
Xwordie_train_df = pd.DataFrame(Xwordie_train,
columns=[str(i)+'_'+str(b) for b in np.arange(1,Xwordie_train.shape[1]+1)])
Xwordie_test_df = pd.DataFrame(Xwordie_test,
columns=[str(i)+'_'+str(b) for b in np.arange(1,Xwordie_test.shape[1]+1)])
df_train = pd.concat([df_train,Xwordie_train_df], axis=1)
df_test = pd.concat([df_test,Xwordie_test_df], axis=1)
self.tfidf_list.append(tfidf)
self.tsvd_list.append(tsvd)
Oh yes, I should explain TSVD.
TSVD, from my own limited understanding, is a reduction method much like Principal Component Analysis (PCA), except that it only ‘shrinks’ vertically. It is commonly used together with TFIDF since TSVD has the ability to ‘merge’ together word vectors that have similar scores in the dataset (in simple stats language, high positive correlation). Such modelling would tend to group together words that belong to similar topics, since they appear in large amounts in a small subset of documents.
So in my case, the end result would be 1500 truncated columns of various ngram range. This method also helps manage computer memory better.
Unfortunately for this method, there is no way we can determine which exact words or phrases influence the results anymore.
Feature removal
Sad to say, there are some features that I just have to remove. For the purpose of my use case (classify text data), it would be unrealistic for such features to be used. Not like we talk about MBTI all the time, do we?
X_train.drop(['n_video','n_links','n_image','n_otherlink','mention_count','hashtag_count','mbti_ref_count','ennea_count',
'bracket_count'], axis=1, inplace=True)
Scaling
I did two types of scaling: Standard Scaling and MinMax Scaling.
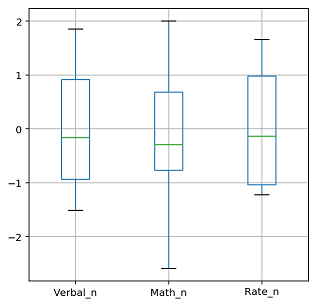
Standard Scaling works to ‘level’ the field across column features. Quite commonly in machine learning execution, we get imbalanced representation where one feature would have a range of 100000 while another probably only has a range of 0.001 (and therefore, the former would significantly affect the scoring function more). What Standard Scaling does is simply subtract each value from the mean and then divide by the standard deviation. Naturally, features with large ranges gets ‘penalized’ more heavily.
I forgot to plot using my own data, so hopefully this imagery from a class project would help:
Before:

After:
MinMax Scaling was done primarily for purpose of the next feature selection technique that I used: Chi square. Chi square selection only works with positive values, so I have to ‘scale up’ the negative values up. What this scaling essentially does is to scale the data to a specified range, namely between 1 and 0.
Under-Sampling the majority class
We still do have imbalanced datasets (for E/I and S/N) which necessitates the use of stratified sampling during the train test split. An imbalanced dataset is generally bad for machine learning as it will tend to predict more readily the majority class. One way to provide the balance is to either under-sample the majority class or to over-sample the minority class. For this project I chose to do the former only.
if imbl:
imbler = RandomUnderSampler(random_state=42)
X_train, y_train = imbler.fit_sample(X_train, y_train)
More Feature reduction!
About Chi Square:
A chi square test measures how related each distribution of data is to the respective categorical variable. So for example
Very useful for binary classifiers, which is why I chose this method.
Anyway! Here are the results in the case of Introversion/Extraversion, top ten!:
| – | Features | Scores | p-value |
|---|---|---|---|
| 37 | 1_15 | 5.958086 | 0.014650 |
| 33 | 1_11 | 5.582567 | 0.018140 |
| 3 | n_caps_char | 4.601679 | 0.031941 |
| 2 | n_caps | 3.875362 | 0.049000 |
| 30 | 1_7 | 3.746265 | 0.052926 |
| 38 | 1_16 | 3.508324 | 0.061061 |
| 28 | 1_3 | 3.445238 | 0.063434 |
| 31 | 1_9 | 3.156438 | 0.075628 |
| 32 | 1_10 | 2.853656 | 0.091166 |
| 27 | 1_2 | 2.413678 | 0.120279 |
Observations:
- Most of the best predictors are single word features. Interesting.
- The p-values shown actually suggests that a large majority of the features available are not exactly useful for differentiating between the target classes, with the p-value inching above 0.05 even within the top ten features (not to mention the other 90, or even the rejected ones!)
Nevertheless, we still use them for modelling.
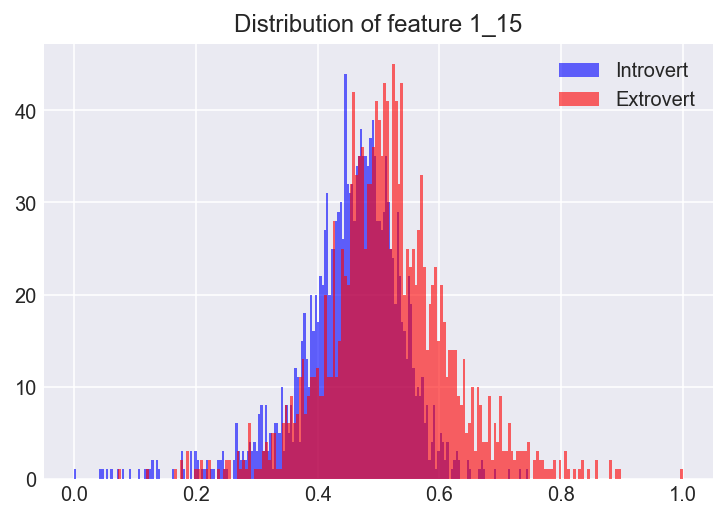
For visualization, here is the distribution chart of feature 1_15. This suggest that there are a group of single words that extroverts use that introverts would use less of, according to the feature.
At long last, modelling!
Using the good old Logistic Regression with lasso penalty,
Result:
Introversion/Extraversion
Score: 0.820749279539
Cross val score: [ 0.8261563 0.80718954 0.81730769 0.82670906 0.80830671]
| type | precision | recall | f1-score | support |
|---|---|---|---|---|
| Introvert | 0.93 | 0.83 | 0.88 | 1335 |
| Extrovert | 0.58 | 0.78 | 0.67 | 400 |
| avg / total | 0.85 | 0.82 | 0.83 | 1735 |
| – | Introvert_pred | Extrovert_pred |
|---|---|---|
| Introvert_true | 1113 | 222 |
| Extrovert_true | 89 | 311 |
Sorry I didn’t really keep records of other models, but this works!
We shall look at other 3 types:
Sensing/Intuition
Score: 0.821902017291
Cross val score: [ 0.83544304 0.82446809 0.83028721 0.83018868 0.83684211]
| type | precision | recall | f1-score | support |
|---|---|---|---|---|
| Intuitive | 0.97 | 0.82 | 0.89 | 1496 |
| Sensing | 0.42 | 0.82 | 0.56 | 239 |
| avg / total | 0.89 | 0.82 | 0.84 | 1735 |
| – | Intuitive_pred | Sensing_pred |
|---|---|---|
| Intuitive_true | 1231 | 265 |
| Sensing_true | 44 | 195 |
Thinking/Feeling
Score: 0.841498559078
Cross val score: [ 0.82605364 0.8696331 0.84748428 0.83333333 0.84507042]
| type | precision | recall | f1-score | support |
|---|---|---|---|---|
| Feeling | 0.85 | 0.86 | 0.85 | 939 |
| Thinking | 0.83 | 0.83 | 0.83 | 796 |
| avg / total | 0.84 | 0.84 | 0.84 | 1735 |
| – | Feeling_pred | Thinking_pred |
|---|---|---|
| Feeling_true | 803 | 136 |
| Thinking_true | 139 | 657 |
Judging/Perceiving
Score: 0.796541786744
Cross val score: [ 0.79491833 0.79855465 0.79597438 0.78405931 0.79851439]
| type | precision | recall | f1-score | support |
|---|---|---|---|---|
| Perceiving | 0.84 | 0.82 | 0.83 | 1048 |
| Judging | 0.73 | 0.77 | 0.75 | 687 |
| avg / total | 0.80 | 0.80 | 0.80 | 1735 |
| – | Perceiving_pred | Judging_pred |
|---|---|---|
| Perceiving_true | 856 | 192 |
| Judging_true | 161 | 526 |
The TPOT fallacy
When, in your data science work, you reached the modelling stage where you need to figure out the best model to use, and the process becomes iterative…
TPOT to the rescue! Given a few random parameters, it will iterate for you all sorts of models with different hyperparameters and even some scaling to give you the best possible model.
from tpot import TPOTClassifier
tpot = TPOTClassifier(generations=10, population_size=30, verbosity=2, scoring='f1')
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_E_try.py')
Generation 1 - Current best internal CV score: 0.817470446061
Generation 2 - Current best internal CV score: 0.817470446061
Generation 3 - Current best internal CV score: 0.817470446061
Generation 4 - Current best internal CV score: 0.817470446061
Generation 5 - Current best internal CV score: 0.818117900031
Generation 6 - Current best internal CV score: 0.818117900031
Generation 7 - Current best internal CV score: 0.818117900031
Generation 8 - Current best internal CV score: 0.819767096337
Generation 9 - Current best internal CV score: 0.819767096337
Generation 10 - Current best internal CV score: 0.819767096337
Best pipeline: LogisticRegression(FastICA(ZeroCount(MaxAbsScaler(input_matrix)), tol=0.1), C=20.0, dual=False, penalty=l1)
Despite the processing from TPOT, it seems that the result still falls of the scores attained from only Logistic Regression as performed earlier. Applying the TPOT model to our test data, Score: 0.665254237288 Absolutely not fantastic.
It happened similarly with other TPOT runs for other 3 MBTI types.
Important life lesson as a data scientist: Do not put your faith into automated things too much, each problem has their own unique solution which can sometimes be simply within the ordinary. Unless you are pressed for time.
What’s next
I wrote another class that would train incoming inputs for use in training (for application!)
Basically I had to condense all the processing code into a class for preprocessing, followed by ‘borrowing’ loads of model instances trained within the instances of the 4 MBTI types.
#Create an instance
Someguy = NewBerd()
#Perform preprocessing for each line of text
for line in mbti_textlist:
Someguy.preprocess(line, web=False)
#Predict!
more_magic(Someguy)
This is the portion that will activate the interactivity portion in my webapp plus Telegram app (or any other applications I can think of using). Fun times ahead, friends!
Limitations
Of course I must address this. As difficult as this process is, a data scientist must know how to criticize their data.
-
Text data exists in so many forms (SMS/Instant messaging, Facebook/Instagram/Forum posts, Twitter tweets, blog entries, articles etc). They each carry their own writing styles, from casual & multiple short messages to huge chunks of formal writing. As mentioned, the dataset is from forum posts which is only one type of writing style. The model would be able to predict a person’s MBTI type more accurately using the person’s forum writing as opposed to the person’s short messages or long articles, for example.
-
Nothing is known with regards to other personal biodata of each MBTI type person (i.e. each data point). We operate under the naive assumption that the level of english, writing styles etc. is the same across all users, regardless of nationality, english as 1st/2nd language, education level and so on. Biodata can help make the model more accurate by potentially introducing significant factors that would translate into improving the variance.
-
On top of the dataset being extracted from a forum, the forum itself is specialized towards discussion of personality types. On the other hand, real life conversations can go pretty much anywhere. By training the data from within the scope of the forum posts, it is possible for overfitting to occur for the model. The way to mitigate such a thing happening is to introduce text data from multiple sources of different genres, but it would be generally difficult to obtain MBTI-labeled data from sources generally outside of the MBTI topic. Another possible way would be for users (of our applications etc) to ‘help’ train the data by providing their own text input plus their own correct MBTI, but this method then would require us then to place full trust on the integrity of the users.
-
Speaking about trust and integrity, this is also the kind of trust that we place in the users recorded in the dataset itself. In actual fact when we go through the questioning test itself, we fall prey to our own biasness or the ambiguity of the questions itself, leading to inaccurate predictions. For purpose of this data project, we must assume that each person’s type is predicted correctly for the majority, large enough to mitigate the inaccuracy by the wrong minority.
-
In a real world scenario, we fall under the spectrum across the two ends of each MBTI pair, instead of an explicit one. So in a sense, if a person is only say 51% extraverted, he/she is already classified as an extrovert. Again, we must assume a normal distribution of people belonging to each type, in order for the model to hold true.
In essence, one should ideally be aware of the limitations that apply when doing their own prediction. This project should by no means serve as a replacement for professional assessment of one’s MBTI type.
Verdict
This project presents an alternative to the traditional method of finding out a person’s MBTI type. To expand on its use, one can also use this tool to find out another person’s MBTI type through the use of text correspondences of the other party. With sufficient data, HR recruiters who already utilizes MBTI typing for their candidate screening can build upon this model to hasten the recruiting process, improving on the overall experience.
With the advent of data collection methods and techniques, who knows to say if this method of using text data could be used to augment other possible methods of typing. While there exists definite methods of determining a person’s type (as the traditional questioning proves), for the progress of society we would like to explore new tools and methodologies that can ease the way we do things. For example, incorporation of handwriting styles to map personality traits (this can be a project in itself!) on top of the content of the writing, observing speech patterns etc..! The possibilities are endless, yet at the same time, scary…
And of course, finding out one’s own MBTI type is always a fun process. This is one of the main reasons that I undertook this project, and also why I am hoping to develop an application for the public’s use and enjoyment.
Future work
On top of predicting a person’s MBTI type, I hope to expand the project further by introducing Enneagram typing (Another personality typology). Unlike this MBTI project however, the Enneagram has 9 types and cannot be considered individually.
Following which, I can also do a comparison to see how each MBTI type corresponds with each Enneagram type.
That is all for now, my friends.